

在如今大数据的时代下,高并发高可用是所有软件开发都追求的目标,为了实现这一目标,缓存的使用是每一个高并发系统都会涉及到的,使用缓存可以保障系统的运行效率,提高系统的健壮性。

前言
在高并发的系统架构中,大量网络请求的并发处理,导致数据库的I/O消耗是非常巨大的,为了快速读取数据,减少网络请求时延,缓解数据库的压力,因此在软件开发中引入了缓存技术。但是在缓存的使用过程中也会遇到一些特殊情况导致缓存失效,常见的缓存失效的情况有三种:缓存穿透、缓存击穿、缓存雪崩。
缓存失效的三种情况
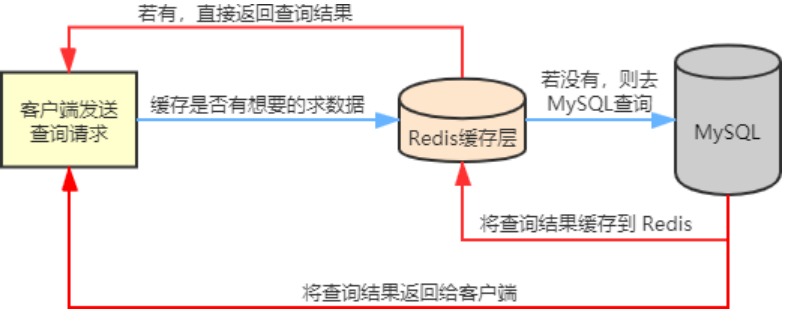
缓存(以Redis缓存为例)的引入可以减少请求数据库的次数,提高查询效率,从而提升系统性能。一般的流程是:应用发起请求后,先查询缓存中是否存在所需数据,如果缓存中存在,直接返回数据,如果缓存中不存在所需数据,则需要去查询数据库,如果数据库中存在所需数据,则一方面存入缓存,另一方面返回查询结果,如果数据库中不存在,则返回空或者错误。
缓存穿透
缓存穿透(Cache Penetration)是指查询一个一定不存在的数据,即用户访问的数据既不在缓存当中,也不在数据库中。由于缓存中查询不到数据,请求会去查询数据库,然而数据库中也不存在该数据,也不会写入缓存,导致查询该数据的时候,每次都要去数据库中查询,给数据库到来压力。
缓存雪崩
缓存雪崩(Cache Avalanche)是指大量的缓存数据在某一时刻超过了缓存的过期时间,同时失效,导致高并发的请求同时去访问数据库,造成数据库压力过大,导致系统崩溃。这是针对多个缓存数据而言的。
缓存击穿
缓存击穿(Cache Breakdown)是指缓存过期的一瞬间,有大量的请求去查询同一个缓存数据,由于该数据在承载着大并发,当该数据失效的一瞬间,持续的大并发就会直接去请求数据库,造成数据库压力倍增。这是针对一个缓存数据而言的。
解决方案
针对缓存穿透的解决方案
第一种方案是采用布隆过滤器进行数据拦截。这也是针对缓存击穿采用的常用方案。在写入数据时,使用布隆过滤器对数据的key进行标记,当带有数据key的请求过来后,先用布隆过滤器验证key是否存在,如果存在,再进入缓存或者数据库中进行查询。
第二种方案是缓存空值。当在数据库中查询不到数据时,将其缓存为空值或者默认值。此时需要注意,针对其的缓存过期时间不宜过长,一般设置为5分钟内,当数据库被写入或者更新该key的新数据时,缓存必须同时更新,保证数据的一致性。
针对缓存雪崩的解决方案
一般是将key的过期时间后面增加一个随机数,让过期时间分散开,使key均匀失效,减少缓存时间过期的重复率。
利用加锁或队列的方式,保证缓存单线程写,但是这种方案会影响并发量,多个请求过来时,只有一个在进行正常的操作,其他请求都会在等待的状态,影响程序性能,不推荐使用。
使用缓存标记,这是比较好的解决办法。判断标记是否过期,过期则去数据库中请求,而缓存数据的过期时间要设置的比缓存标记长些,如此一来,当一个请求去操作数据库的时候,其他的请求拿到的是上一次的缓存数据。
针对缓存击穿的解决方案
使用互斥锁,当缓存的key过期时,多个请求过来时只允许一个请求去查询数据库构建缓存,其他请求等待该请求执行完毕之后,重新从缓存中获取数据。
针对访问量比较大的数据,即热点数据,不设置缓存过期时间,后台异步更新缓存,适用于不严格要求缓存一致性的场景。
以上就是良许教程网为各位朋友分享的Linu系统相关内容。想要了解更多Linux相关知识记得关注公众号“良许Linux”,或扫描下方二维码进行关注,更多干货等着你 !

 微信扫一扫打赏
微信扫一扫打赏
 支付宝扫一扫打赏
支付宝扫一扫打赏

.png)

.jpg){kind=link}