

缓存雪崩指的是大片大片的缓存数据同时过期失效,再加上高并发的请求进入到慢设备,慢设备压力剧增,有可能导致慢设备宕机,这便是缓存雪崩。
上次我们讨论了在分布式系统下的缓存架构体系,从浏览器缓存到客户端缓存,再到CDN缓存,再到反向代理缓存,再到本地缓存,再到分布式缓存。整个链路中有非常多的缓存。
在整个缓存链路,存在各种各样的问题,常见的问题有缓存穿透、缓存击穿、缓存雪崩、缓存数据一致性问题等。不常见的问题有缓存倾斜、缓存阻塞、缓存慢查询、缓存主从一致性问题、缓存高可用、缓存故障发现与故障恢复、集群扩容收缩、大Key热Key等等。
今天我们就来聊聊:缓存雪崩
缓存雪崩,顾名思义,是缓存崩了。如果这样理解的话,那就错了,请跟我来一探究竟吧。
老规矩,先看一下本文大纲:
什么是缓存雪崩
缓存雪崩的痛点有哪些
缓存雪崩的解决思路
总结
什么是缓存雪崩
我们知道,缓存的工作原理是先从缓存中获取数据,如果有数据则直接返回给用户,如果没有数据则从慢速设备上读取实际数据并且将数据放入缓存。就像这样:

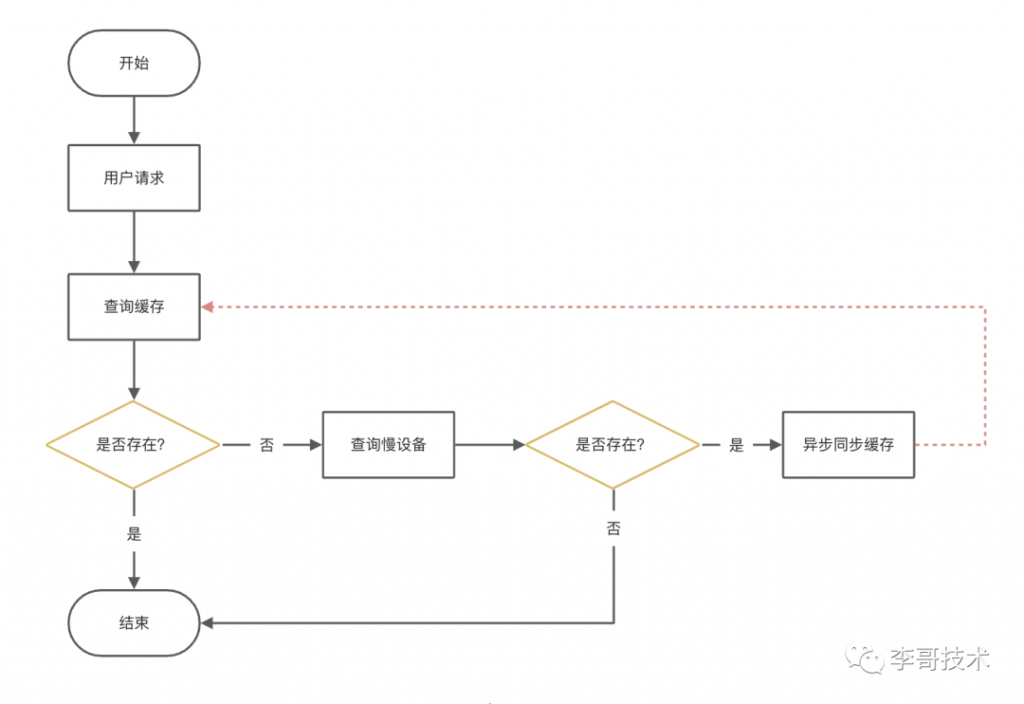
缓存里面的数据有很多,如果有一个key过期,那么就需要回溯查询,如果这个key是热点key,慢设备压力剧增,有可能导致慢设备宕机。就像这样:

这便是我们之前说的:缓存击穿
那如果是很多key都过期了,那请求都会透过缓存层,直奔慢设备了,如果这些失效的key的请求之和很大,那么慢设备压力剧增,有可能导致慢设备宕机。就像这样:
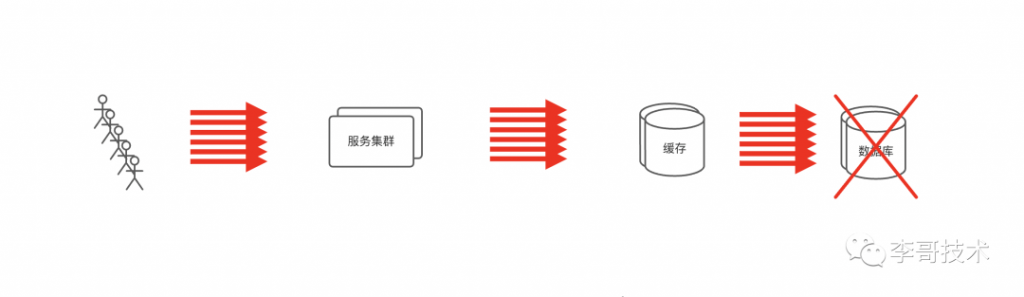
这便是我们今天的主题:缓存雪崩
没错,从上面的含义其实已经能够理解出一个区别:
缓存击穿强调单Key过期+高并发;
缓存雪崩强调多key过期+高并发。
(所以,缓存雪崩不是缓存崩了,是一大片大片的缓存数据都在同一时间都失效了)
雪崩,实在是太可怕了。
缓存雪崩的痛点有哪些
1.热点数据扎堆过期
2.缓存层瞬间透明化
3.慢设备层有被击垮的风险
大家猜想一下,为什么会瞬间有大量数据过期呢?
有两个方向,其一是大量数据同时放入缓存+过期时间设置的时间是一致的;其二是大量数据放入缓存的时间点不一样,但是过期时间是同一时间过期。
其一比较好理解,给大家举几个场景就更好了理解了,比如系统在启动的时候或者每天定时的对大量数据进行预热,并且过期时间是一样的。又或者是大促,商品在同一时刻开放,大量的用户进行不同商品的访问,这些商品数据几乎同时进入缓存,并且过期时间是一样的。
其二不太容易理解,给大家举个场景就好了。比如有一个给用户推送消息的需求,但是一天只允许推送一次,假设给张三同学早上8点推送,那么可以将这条数据放入缓存,过期时间为16小时,再次给张三推送的时候检查缓存是否存在,缓存存在则不允许推送了,缓存不存在则允许推送。给李四同学下午14点推送了一条消息,那么给李四同学放缓存的数据过期时间应该是10小时。这个场景就解释了在不同的时间点放入的数据,它们的过期时间不一样,但是都是在同一时刻过期(在这个例子中是每天0点过期)。
缓存雪崩的解决思路
1.从上述的其一来看,是数据放入缓存的时间和过期时间一样,所以最终大量数据同一时间过期。
所以,我们从这一点来看,我们可以改变数据放入缓存的的时间,也可以选择修改数据的过期时间,让过期时间不一致,最终的目的是让数据分散在不同的时间点过期,从而减少数据库的高并发压力。很显然,修改数据的过期时间更简单一些,让缓存时间在一定的区域随机取值,很轻松就能解决了一个缓存雪崩的问题。
2.当然了,问题的产生是数据过期了,所以还有一种解决方案是:让你的数据永不过期!显然,你的leader或者身为leader的你是不会这么玩的,这个方案基本不可行。原因是就算让缓存数据在缓存永不过期,那难道缓存敢保证100%保证可用吗?不敢,所以,你还是需要准备planB,做好缓存宕机或者缓存数据不存在的备案。
3.既然是因为并发访问导致,我们是不是可以由高并发转换低并发,称之为互斥锁,或者分布式锁等,总之,加锁来保证高并发转换成低并发。
4.我们继续分析,像这种热点数据,是不是应该由热点服务器去完成,对吧?我们应该去做隔离机制,如果你有一套实时热点发现系统,再加上热点流量自动迁移到热点服务器,就算有这些有什么用,能解决问题吗?答案是不能,因为热点服务器仍然是需要防止缓存雪崩的,方案在上面已经提到过了就不再赘述了。这里只是抛砖引玉,浅谈环境隔离与实时热点发现。
5.继续,既然是数据库承受不住了,我们在知道问题的情况下,可以对数据做离散分布,让它均匀地分布在我们的分布式数据库中,同时对数据库尽量的水平扩容,常见的分库分表策略有32库32表,64库64表,128库128表……,这样做的目的是让单台数据库压力变小,从而防止缓存雪崩。
6.继续分析,我们从现象来看,是数据库宕机了,原因是数据库接受到的瞬间请求太多了,数据库扛不住压力所以就停止工作了。那我们是不是可以这么分析,如果我们提前知道数据库能承受的最大阈值是多少,并且提前设置好数据库的阈值或者服务的阈值,如果瞬间流量来了,我们把超过阈值的流量进行排队等待或者直接拒绝服务,保证数据库的压力是不超过阈值的,是不是也能解决缓存雪崩所带来的影响呢?
那么这里面有涉及到几个数据:数据库的阈值从何得知、服务的阈值从何得知、如何设置数据库或者服务的阈值。
答案是:数据的阈值应该是压测后得出,而设置阈值应该是在网关层进行限流处理,所以你需要有这样的限流平台。
对于压测和网关,我们后续会有专门的文章来讨论,本期暂且不深入了,敬请期待。可以关注我的公中号:李哥技术
总结
其实缓存雪崩的理解很简单,为什么说得这么复杂,原因很简单,就是不想让大家用背八股文一样的方式去记忆,而是靠深入理解它的痛点然后逐步分析解决方案去记忆。
来总结一下吧。
概念:缓存雪崩指的是大片大片的缓存数据同时过期失效,再加上高并发的请求进入到慢设备,慢设备压力剧增,有可能导致慢设备宕机,这便是缓存雪崩。
解决方案:
1.修改数据放入缓存的时间,或修改数据在缓存中的过期时间;
2.让缓存数据永不过期;
3.互斥锁,由高并发转换成低并发,保护DB;
4.热点隔离,实时热点发现系统;
5.水平扩容数据库,压力平摊,保护DB;
6.提前压测,得出阈值,限流处理,保护服务与DB;
好了,本期缓存雪崩的解决思路就到这里了,感谢阅读!
以上就是良许教程网为各位朋友分享的Linu系统相关内容。想要了解更多Linux相关知识记得关注公众号“良许Linux”,或扫描下方二维码进行关注,更多干货等着你 !

 微信扫一扫打赏
微信扫一扫打赏
 支付宝扫一扫打赏
支付宝扫一扫打赏

.png)

.jpg){kind=link}