

最近我一直在使用Nordic的52832开发,这是一种属于ARM Cortex M4架构的芯片。其中,我想要强调的是M4与M0、M3之间最大的不同就是具备了FPU(浮点运算单元),而这正是我项目中需要的功能。
由于项目中使用了卡尔曼滤波等算法,需要支持浮点指令集,因此速度非常重要。在使用CMSIS DSP软件库的数学库arm_math之后,我发现在处理数学运算时,相比于M0/M3,M4能够提供数十倍甚至上百倍的性能。
现在,让我来解释一下CMSIS DSP软件库是什么。
CMSIS DSP软件库是一套常用于基于Cortex-M和Cortex-A处理器的设备的信号处理功能。该库涵盖了以下几个类别的功能:
-
基本的数学功能 -
快速的数学功能 -
复杂的数学函数 -
过滤功能 -
矩阵函数 -
转换功能 -
电机控制功能 -
统计功能 -
支持功能 -
插值功能 -
支持向量机功能(SVM) -
贝叶斯分类器功能 -
距离功能
该库通常提供单独的函数来处理不同类型的数据,包括8位整数、16位整数、32位整数和32位浮点数。
库的使用介绍
库安装程序在Lib文件夹中包含库的预构建版本,以下是预构建库的列表:
-
arm_cortexM7lfdp_math.lib(Cortex-M7,小端,双精度浮点单元) -
arm_cortexM7bfdp_math.lib(Cortex-M7,大字节序,双精度浮点单元) -
arm_cortexM7lfsp_math.lib(Cortex-M7,小端,单精度浮点单元) -
arm_cortexM7bfsp_math.lib(Cortex-M7,大字节序和单精度浮点单元打开) -
arm_cortexM7l_math.lib(Cortex-M7,小端) -
arm_cortexM7b_math.lib(Cortex-M7,大端) -
arm_cortexM4lf_math.lib(Cortex-M4,小端,浮点单元) -
arm_cortexM4bf_math.lib(Cortex-M4,大端,浮点单元) -
arm_cortexM4l_math.lib(Cortex-M4,小端) -
arm_cortexM4b_math.lib(Cortex-M4,大端) -
arm_cortexM3l_math.lib(Cortex-M3,小端) -
arm_cortexM3b_math.lib(Cortex-M3,大端) -
arm_cortexM0l_math.lib(Cortex-M0 / Cortex-M0 +,小端) -
arm_cortexM0b_math.lib(Cortex-M0 / Cortex-M0 +,大端) -
arm_ARMv8MBLl_math.lib(Armv8-M基线,小端) -
arm_ARMv8MMLl_math.lib(Armv8-M主线,小端) -
arm_ARMv8MMLlfsp_math.lib(Armv8-M主线,小字节序,单精度浮点单元) -
arm_ARMv8MMLld_math.lib(Armv8-M主线,小端,DSP指令) -
arm_ARMv8MMLldfsp_math.lib(Armv8-M主线,小字节序,DSP指令,单精度浮点单元)
库函数在位于Include文件夹中的公共文件arm_math.h中声明,只需包括此文件并在应用程序中链接适当的库,然后开始调用库函数就可以使用了。
该库支持带有小尾数和大尾数的Cortex-M内核,相同的头文件将用于浮点单元(FPU)变体。
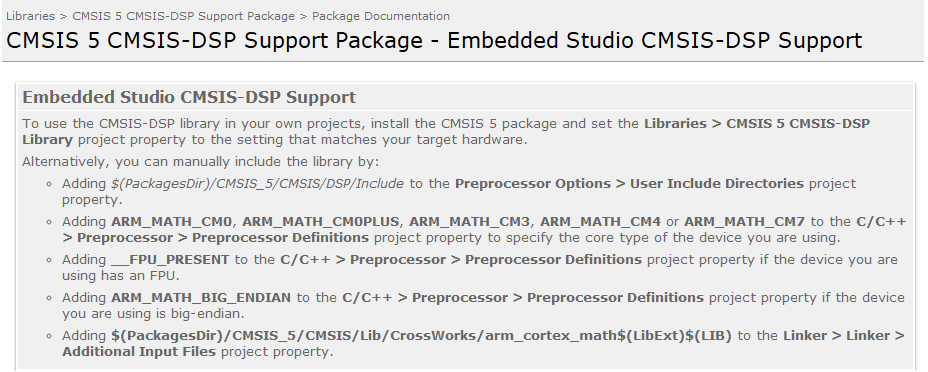
使用Segger Embedded Studio如何添加配置
在tools-->Package Mangner里面可以直接安装,CMSIS 5 CMSIS-DSP Support Package这里我已经装了
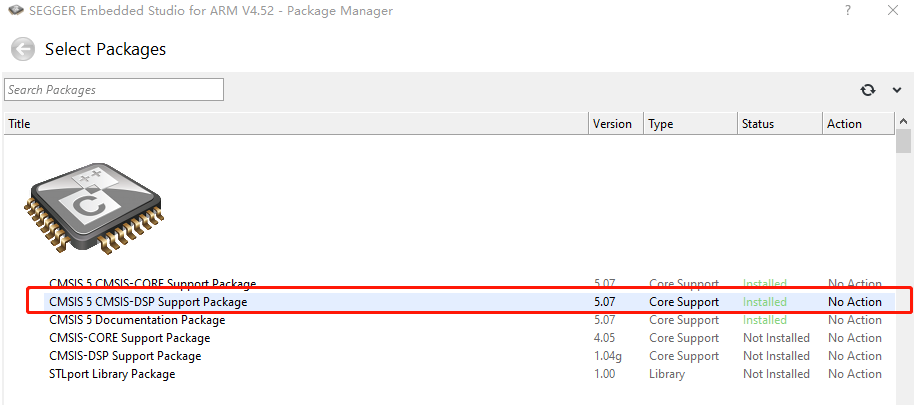
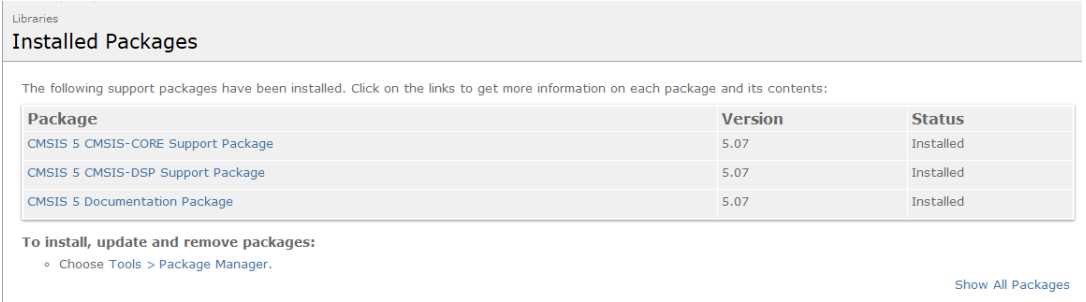
也可以点击已经安装的库,显示如下图
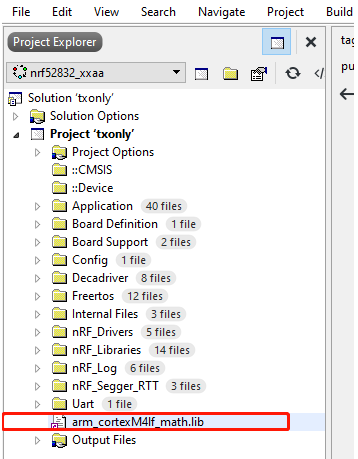
然后添加到工程里面,我使用的是arm_cortexM4lf_math.lib,如下图
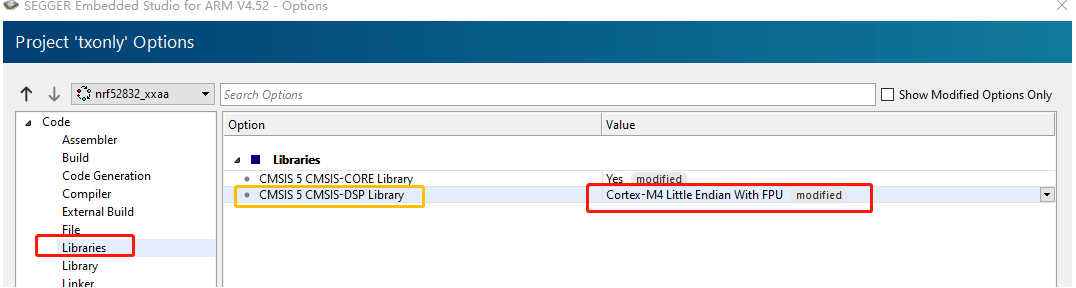
使用Segger Embedded Studio还需要在工程里设置一下如下图所示
CMSIS DSP软件库文件结构
下图所示为DSP_Lib的文件结构

下面是各个源文件的使用说明
-
BasicMathFunctions
提供浮点数的各种基本运算函数,如加减乘除等运算。对于M0/M3只能用Q运算,即文件夹下以_q7、_q15、_q31结尾的文件;而M4F能直接进行硬件浮点计算,属于文件夹下以_f32结尾的文件。
-
CommonTables
arm_common_tables.c文件提供位翻转参数表。
-
ComplexMathFunctions
复述数学功能,如向量处理,求模运算等。
-
ControllerFunctions
控制功能,主要为PID控制函数。
-
FastMathFunctions
快速数学功能函数,提供256点正余弦函数表和任意任意角度的正余弦函数值计算功能,和Q值开平方运算:
-
Arm_cos_f32/_q15/_q31.c:提供256点余弦函数表和任意角度余弦值计算功能。 -
Arm_sin_f32/_q15/_q31.c:提供256点正弦函数表和任意角度正弦值计算功能。 -
Arm_sqrt_q15/q31.c:提供迭代法计算平方根的函数。对于M4F的平方根运算,通过执行VSQRT指令完成。 -
FilteringFunctions
滤波函数功能,主要为FIR和LMS(最小均方根)滤波函数。
-
MatrixFunctions
矩阵处理函数。
-
StatisticsFunctions
统计功能函数,如求平均值、计算RMS、计算方差/标准差等。
-
SupportFunctions
支持功能函数,如数据拷贝,Q格式和浮点格式相互转换,Q任意格式相互转换。
-
TransformFunctions
变换功能,包括复数FFT(CFFT)/复数FFT逆运算(CIFFT)、实数FFT(RFFT)/实数FFT逆运算(RIFFT)、和DCT(离散余弦变换)和配套的初始化函数。
预处理器宏
-
ARM_MATH_BIG_ENDIAN:
定义宏ARM_MATH_BIG_ENDIAN来为大型字节序目标构建库。默认情况下,为小端目标建立库。
-
ARM_MATH_MATRIX_CHECK:
定义宏ARM_MATH_MATRIX_CHECK以检查矩阵的输入和输出大小。
-
ARM_MATH_ROUNDING:
定义宏ARM_MATH_ROUNDING来舍入支持函数。
-
ARM_MATH_LOOPUNROLL:
定义宏ARM_MATH_LOOPUNROLL以启用DSP函数中的手动循环展开
-
ARM_MATH_NEON:
定义宏ARM_MATH_NEON以启用DSP功能的Neon版本。当Neon可用时,默认情况下不启用它,因为性能取决于编译器和目标体系结构。
-
ARM_MATH_NEON_EXPERIMENTAL:
定义宏ARM_MATH_NEON_EXPERIMENTAL以启用某些DSP功能。
-
ARM_MATH_HELIUM:
意味着标志ARM_MATH_MVEF和ARM_MATH_MVEI和ARM_MATH_FLOAT16。
-
ARM_MATH_MVEF:
选择f32算法的,意味着ARM_MATH_FLOAT16和ARM_MATH_MVEI。
-
ARM_MATH_MVEI:
选择int和定点算法的版本。
-
ARM_MATH_FLOAT16:
一些算法的Float16实现(需要MVE扩展)。
应用以及测试
在扩展卡尔曼滤波里面有很多矩阵求逆等等运算,如下面这个函数
_Bool matrixAddF(DOUBLE_TEST* result, DOUBLE_TEST* m, unsigned int row, unsigned int col, DOUBLE_TEST add) {
DOUBLE_TEST dt[row*col];
memset(dt, add, sizeof(DOUBLE_TEST)*row*col);
unsigned int i, j;
for (i = 0; i for (j = 0; j return true;
}
使用数学函数加速可以更改为
_Bool matrixAddF(DOUBLE_TEST* result, DOUBLE_TEST* m, unsigned int row, unsigned int col, DOUBLE_TEST add) {
DOUBLE_TEST dt[row*col];
memset(dt, add, sizeof(DOUBLE_TEST)*row*col);
arm_mat_init_f32(&mtrin1, row, col, m);
arm_mat_init_f32(&mtrin2, row, col, dt);
arm_mat_init_f32(&mtrout, row, col, result);
arm_mat_add_f32(&mtrin1, &mtrin2, &mtrout);
再举一个例子
_Bool matrixMult(DOUBLE_TEST* result, DOUBLE_TEST* m1, unsigned int row1, unsigned int col1, DOUBLE_TEST* m2, unsigned int row2, unsigned int col2) {
if (col1 != row2)
return false;
unsigned int i, j, k;
unsigned int M, N;
M = row1;
N = col2;
DOUBLE_TEST sum = 0;
for (i = 0; i for (j = 0; j for (k = 0; k return true;
}
可以更改为
_Bool matrixMult(DOUBLE_TEST* result, DOUBLE_TEST* m1, unsigned int row1, unsigned int col1, DOUBLE_TEST* m2, unsigned int row2, unsigned int col2) {
if (col1 != row2)
return false;
arm_mat_init_f32(&mtrin1, row1, col1, m1);
arm_mat_init_f32(&mtrin2, row2, col2, m2);
arm_mat_init_f32(&mtrout, row1, col2, result);
arm_mat_mult_f32(&mtrin1, &mtrin2, &mtrout);
return true;
}
arm_mat_init_f32的定义在arm_math.h里面,如下
/**
* 浮点矩阵初始化
* [in,out] S points to an instance of the floating-point matrix structure.
* [in] nRows number of rows in the matrix.
* [in] nColumns number of columns in the matrix.
* [in] pData points to the matrix data array.
*/
void arm_mat_init_f32(
arm_matrix_instance_f32 * S,
uint16_t nRows,
uint16_t nColumns,
float32_t * pData);
arm_mat_add_f32函数如下
/**
* 浮点矩阵加法
* [in] pSrcA points to the first input matrix structure
* [in] pSrcB points to the second input matrix structure
* [out] pDst points to output matrix structure
* return The function returns either
*/
arm_status arm_mat_add_f32(
const arm_matrix_instance_f32 * pSrcA,
const arm_matrix_instance_f32 * pSrcB,
arm_matrix_instance_f32 * pDst);
arm_mat_sub_f32函数如下
/**
* 浮点矩阵减法
* [in] pSrcA points to the first input matrix structure
* [in] pSrcB points to the second input matrix structure
* [out] pDst points to output matrix structure
* return The function returns either
*/
arm_status arm_mat_sub_f32(
const arm_matrix_instance_f32 * pSrcA,
const arm_matrix_instance_f32 * pSrcB,
arm_matrix_instance_f32 * pDst);
上面几个函数中出现的结构体arm_status、arm_matrix_instance_f32定义如下
/**
* 库中某些函数返回的错误状态。
*/
typedef enum
{
ARM_MATH_SUCCESS = 0, /**-a-number (NaN) or infinity is generated */
ARM_MATH_SINGULAR = -5, /**经过测试,使用硬件加速之后,我的程序运行速度增加了10倍,跑一下扩展卡尔曼滤波也不算慢了。
以上就是良许教程网为各位朋友分享的Linu系统相关内容。想要了解更多Linux相关知识记得关注公众号“良许Linux”,或扫描下方二维码进行关注,更多干货等着你 !
 微信扫一扫打赏
微信扫一扫打赏
 支付宝扫一扫打赏
支付宝扫一扫打赏

.png)

.jpg){kind=link}