

Hadoop是一个能够对大量数据进行分布式处理的软件框架,Hadoop拥有着高可靠性、高扩展性、高容错性等特点成为大数据中主流的框架。

本文将帮助你逐步在 CentOS 上安装 hadoop 并配置单节点 hadoop 集群。
安装 Java
在安装 hadoop 之前,请确保你的系统上安装了 Java。使用此命令检查已安装 Java 的版本。
java -versionjava version "1.7.0_75"Java(TM) SE Runtime Environment (build 1.7.0_75-b13)Java HotSpot(TM) 64-Bit Server VM (build 24.75-b04, mixed mode)
要安装或更新 Java,请参考下面逐步的说明。
第一步是从 Oracle 官方网站下载最新版本的 java。
cd /opt/wget --no-cookies --no-check-certificate --header "Cookie: gpw_e24=http%3A%2F%2Fwww.oracle.com%2F; oraclelicense=accept-securebackup-cookie" "http://download.oracle.com/otn-pub/java/jdk/7u79-b15/jdk-7u79-linux-x64.tar.gz"tar xzf jdk-7u79-linux-x64.tar.gz
需要设置使用更新版本的 Java 作为替代。使用以下命令来执行此操作。
cd /opt/jdk1.7.0_79/alternatives --install /usr/bin/java java /opt/jdk1.7.0_79/bin/java 2alternatives --config java
There are 3 programs which provide 'java'.Selection Command-----------------------------------------------* 1 /opt/jdk1.7.0_60/bin/java+ 2 /opt/jdk1.7.0_72/bin/java3 /opt/jdk1.7.0_79/bin/javaEnter to keep the current selection[+], or type selection number: 3 [Press Enter]
现在你可能还需要使用 alternatives 命令设置 javac 和 jar 命令路径。
alternatives --install /usr/bin/jar jar /opt/jdk1.7.0_79/bin/jar 2alternatives --install /usr/bin/javac javac /opt/jdk1.7.0_79/bin/javac 2alternatives --set jar /opt/jdk1.7.0_79/bin/jaralternatives --set javac /opt/jdk1.7.0_79/bin/javac
下一步是配置环境变量。使用以下命令正确设置这些变量。
设置 JAVA_HOME 变量:
export JAVA_HOME=/opt/jdk1.7.0_79
设置 JRE_HOME 变量:
export JRE_HOME=/opt/jdk1.7.0_79/jre
设置 PATH 变量:
export PATH=$PATH:/opt/jdk1.7.0_79/bin:/opt/jdk1.7.0_79/jre/bin
安装 Apache Hadoop
设置好 java 环境后。开始安装 Apache Hadoop。
第一步是创建用于 hadoop 安装的系统用户帐户。
useradd hadooppasswd hadoop
现在你需要配置用户 hadoop 的 ssh 密钥。使用以下命令启用无需密码的 ssh 登录。
su - hadoopssh-keygen -t rsacat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keyschmod 0600 ~/.ssh/authorized_keysexit
现在从官方网站 hadoop.apache.org 下载 hadoop 最新的可用版本。
cd ~wget http://apache.claz.org/hadoop/common/hadoop-2.6.0/hadoop-2.6.0.tar.gztar xzf hadoop-2.6.0.tar.gzmv hadoop-2.6.0 hadoop
下一步是设置 hadoop 使用的环境变量。
编辑 ~/.bashrc,并在文件末尾添加以下这些值。
export HADOOP_HOME=/home/hadoop/hadoopexport HADOOP_INSTALL=$HADOOP_HOMEexport HADOOP_MAPRED_HOME=$HADOOP_HOMEexport HADOOP_COMMON_HOME=$HADOOP_HOMEexport HADOOP_HDFS_HOME=$HADOOP_HOMEexport YARN_HOME=$HADOOP_HOMEexport HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/nativeexport PATH=$PATH:$HADOOP_HOME/sbin:$HADOOP_HOME/bin
在当前运行环境中应用更改。
source ~/.bashrc
编辑 $HADOOP_HOME/etc/hadoop/hadoop-env.sh 并设置 JAVA_HOME 环境变量。
export JAVA_HOME=/opt/jdk1.7.0_79/
现在,先从配置基本的 hadoop 单节点集群开始。
首先编辑 hadoop 配置文件并进行以下更改。
cd /home/hadoop/hadoop/etc/hadoop
让我们编辑 core-site.xml。
fs.default.name hdfs://localhost:9000
接着编辑 hdfs-site.xml:
dfs.replication 1 dfs.name.dir file:///home/hadoop/hadoopdata/hdfs/namenode dfs.data.dir file:///home/hadoop/hadoopdata/hdfs/datanode
并编辑 mapred-site.xml:
mapreduce.framework.name yarn
最后编辑 yarn-site.xml:
yarn.nodemanager.aux-services mapreduce_shuffle
现在使用以下命令格式化 namenode:
hdfs namenode -format
要启动所有 hadoop 服务,请使用以下命令:
cd /home/hadoop/hadoop/sbin/start-dfs.shstart-yarn.sh
要检查所有服务是否正常启动,请使用 jps 命令:
jps
你应该看到这样的输出。
26049 SecondaryNameNode25929 DataNode26399 Jps26129 JobTracker26249 TaskTracker25807 NameNode
现在,你可以在浏览器中访问 Hadoop 服务:http://your-ip-address:8088/ 。
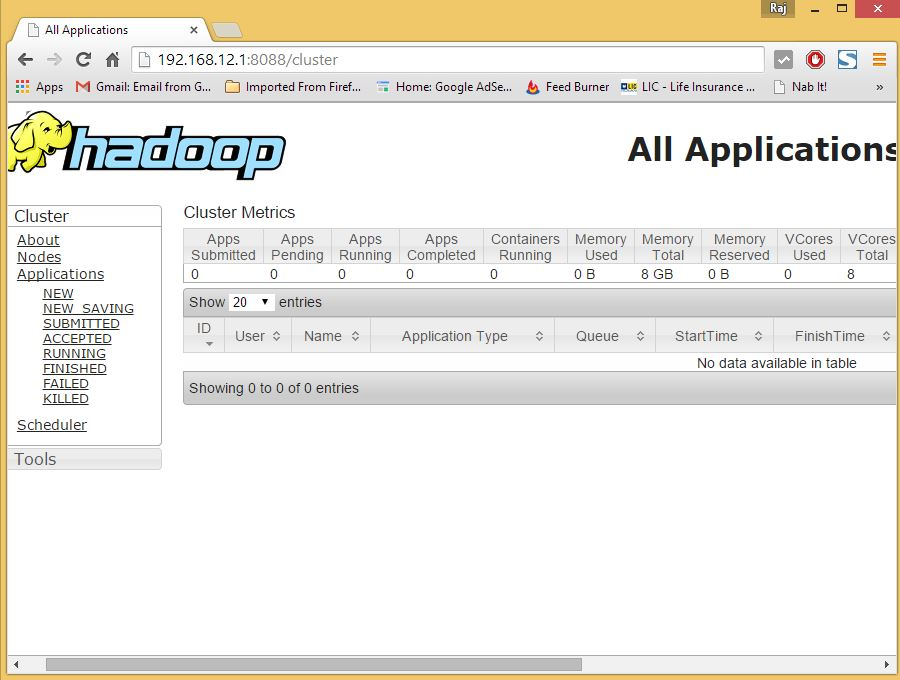
关于在 CentOS 上安装 Apache Hadoop的教程分享结束大家有什么建议可以在评论区分享啊。
为各位朋友分享的相关内容。想要了解更多Linux相关知识记得关注公众号“良许Linux”,或扫描下方二维码进行关注,更多

 微信扫一扫打赏
微信扫一扫打赏
 支付宝扫一扫打赏
支付宝扫一扫打赏

.png)

.jpg){kind=link}